1. MapReduce definition
MapReduce in Hadoop is a simple software framework based on which an application can run on a large cluster of thousands of commercial machines and process terabytes of data in parallel with a reliable fault tolerance.
2. MapReduce Features
Why is MapReduce so popular? Especially in the Internet+ era, Internet+ companies are using MapReduce. The reason why MapReduce is so popular is that it has the following characteristics.
- MapReduce is easy to program. It simply implements some interfaces to complete a distributed program that can be distributed to a large number of inexpensive PC machines. In other words, you write a distributed program that is exactly the same as writing a simple serial program. It is because of this feature that makes MapReduce programming very popular.
- Good scalability. When your computing resources are not being met, you can extend its computing power by simply adding machines.
- High tolerance. The original intention of MapReduce design is to enable programs to be deployed on inexpensive PC machines, which requires high fault tolerance. For example, if one of the machines hangs, it can transfer the above computing task to another node to run, so that the task fails to run, and the process does not require manual participation, but is completely done internally by Hadoop.
- Suitable for offline processing of PB level data in Shanghai. Here, the red font is processed offline, indicating that it is suitable for offline processing and not suitable for online processing. For example, returning a result like the millisecond level, MapReduce is difficult to do.
Although MapReduce has many advantages, it also has some advantages. Not good at this point does not mean that it can't be done, but it is not effective in some scenarios. It is not suitable for MapReduce to deal with, mainly in the following aspects.
- Real time calculations. MapReduce cannot return results in milliseconds or seconds like Mysql.
- Streaming calculations. Streaming computed input data is dynamic, while MapReduce's input dataset is static and cannot be dynamically changed. This is because the design features of MapReduce itself determine that the data source must be static.
- DAG (directed graph) calculation. There are dependencies on multiple applications, and the input from the latter application is the previous output. In this case, MapReduce is not impossible to do, but after use, the output of each MapReduce job will be written to disk, which will cause a lot of disk IO, resulting in very low performance.
3. MapReduce architecture
Like HDFS, MapReduce also uses the Master/Slave architecture, and its architecture is shown below.
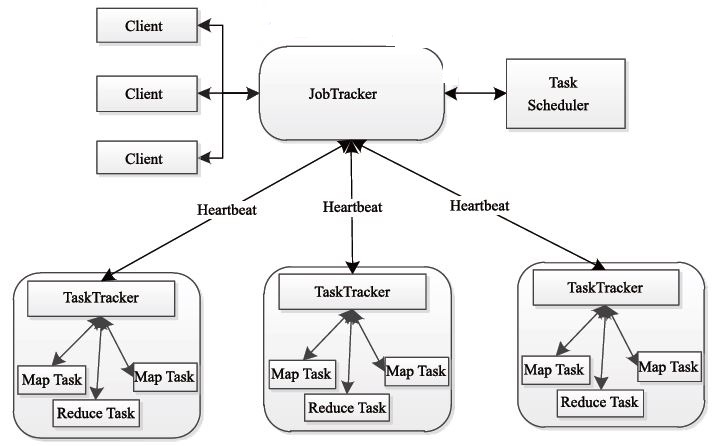
MapReduce consists of four components, namely Client, JobTracker, TaskTracker and Task. We will introduce these four components in detail below.
1) Client client
Each job will package the application and configuration parameter Configuration into a JAR file on the client side and store it in the HDFS via the Client class, and submit the path to the JobTracker's master service. Then each master will create each Task (ie MapTask and ReduceTask). Distribute to each TaskTracker service for execution.
2) JobTracker
JobTracke is responsible for resource monitoring and job scheduling. JobTracker monitors the health of all TaskTrackers and jobs. Once the discovery fails, the corresponding tasks are transferred to other nodes. At the same time, JobTracker tracks the progress of the tasks, resource usage and other information, and tells the task scheduler. The scheduler chooses the appropriate tasks to use when the resources are idle. In Hadoop, the task scheduler is a pluggable module, and users can design the appropriate scheduler according to their needs.
3) TaskTracker
TaskTracker periodically reports the usage of resources on the node and the running progress of the task to the JobTracker through Heartbeat, and receives the commands sent by the JobTracker and performs corresponding operations (such as starting new tasks, killing tasks, etc.). TaskTracker uses "slot" to divide the amount of resources on this node. "slot" represents computing resources (CPU, memory, etc.). A Task has a chance to run after getting a slot, and the Hadoop scheduler is used to assign idle slots on each TaskTracker to the Task. The slot is divided into Map slot and Reduce slot, which are used by Map Task and Reduce Task respectively. The TaskTracker limits the concurrency of the Task by the number of slots (configurable parameters).
4) Task
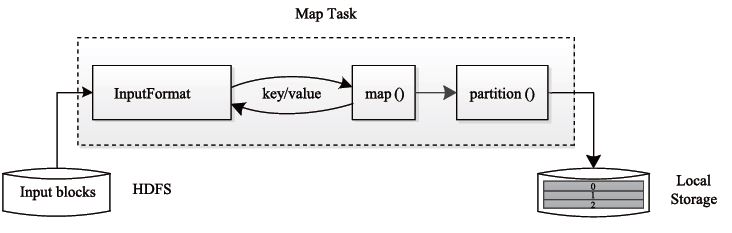
The Task is divided into Map Task and Reduce Task, both of which are started by TaskTracker. HDFS stores data in a fixed-size block, and for MapReduce, the processing unit is split.
The Map Task execution process is shown in the following figure: As shown in the figure, the Map Task first resolves the corresponding split iteration into a key/value pair, and then calls the user-defined map() function to process it, and finally stores the temporary result. On the local disk, the temporary data is divided into several partitions, and each partition is processed by a Reduce Task.
The Reduce Task execution process is shown in the figure below. The process is divided into three phases:
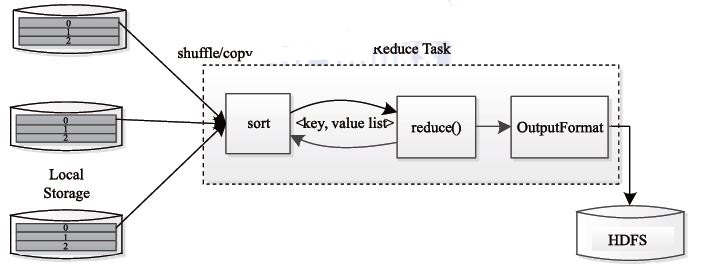
1 Read the Map Task intermediate result (called "Shuffle stage") from the remote node;
2 Sort the key/value pairs by key (called "Sort phase");
3 Read <key, value list> in turn, call the user-defined reduce() function, and save the final result to HDFS (called "Reduce stage").
4. MapReduce internal logic
Below we analyze the data processing of MapReduce through the internal logic of MapReduce. Let's take the WordCount as an example to see the internal logic of mapreduce, as shown in the following figure.
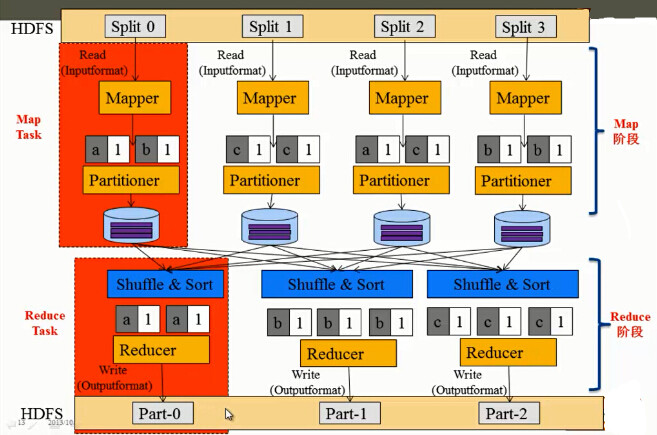
The general flow of MapReduce internal logic is mainly done in the following steps.
1. First, the data in HDFS is used as the input of MapReduce in Split mode. As we mentioned earlier, the data in HDFS is stored in blocks. How do you turn it into Split as input? In fact, block is a term in HDFS, and Split is a term in MapReduce. By default, a split can correspond to a block, of course, it can correspond to multiple blocks, and the correspondence between them is determined by InputFormat. By default, TextInputFormat is used, in which case one Split corresponds to a block. Suppose there are 4 blocks, that is, 4 Splits, which are Split0, Split1, Split2, and Split3. At this time, the data in each Split is read by InputFormat, which parses the data into a single (key, value) and then passes it to the already written Mapper function for processing.
2. Each Mapper parses the input (key, value) data into a single word and word frequency, such as (a, 1), (b, 1) and (c, 1) and so on.
3. In the reduce phase, each reduce needs to perform shuffle to read the data corresponding to it. After all the data has been read, it will be sorted by Sort, and then sorted and then submitted to Reducer for statistical processing. For example, the first Reducer reads two (a, 1) key-value pairs and then counts the results (a, 2).
4. Output the result of the Reducer to the file path of HDFS in the format of OutputFormat. The OutputFormat here defaults to TextOutputFormat, the key is the word, the value is the word frequency, and the separator between the key and the value is "\tab". As shown in the figure above, (a 2) is output to Part-0, (b 3) is output to Part-1, and (c 3) is output to Part-2.








